OCR (оптическое распознавание символов) — это технология, позволяющая преобразовывать изображения текста в машиночитаемые форматы. Она используется для сканирования документов, распознавания текста на фотографиях и упрощения обработки больших объемов информации. С помощью OCR можно извлекать текст из различных форматов и преобразовывать его в редактируемые документы, такие как Word или PDF.
Технология OCR находит применение в различных областях, включая автоматизацию офисных процессов, архивацию документов и создание баз данных. С каждым годом алгоритмы распознавания становятся более точными и быстрыми, что улучшает качество распознавания и расширяет возможности использования этой технологии в повседневной жизни.
Системы оптического распознавания
Оптическое распознавание текста (OCR) — это технология, которая позволяет компьютерам преобразовывать изображения, содержащие текст, в формат, удобный для чтения машинами. С помощью OCR системы могут извлекать и интерпретировать текст, что открывает возможности для поиска, редактирования и автоматической обработки информации.
Эта технология имеет высочайшее значение в различных сферах. В бизнесе она содействует автоматизации обработки документов, повышает точность ввода информации и способствует улучшению эффективности работы. В медицине OCR находит применение для распознавания рецептов, медицинских записей и идентификации пациентов. В сфере безопасности и видеонаблюдения системы OCR способны распознавать номерные знаки автомобилей и лица. В транспортной отрасли OCR используется для автоматической идентификации и классификации грузов и контейнеров.
Актуальные системы строятся на сочетании множества технологий, среди которых — обработка изображений, алгоритмы машинного обучения и нейронные сети. Системы оптического распознавания символов (OCR) имеют возможность обрабатывать текст на различных языках, включая рукописные записи. Кроме того, они эффективно справляются с разнообразными шрифтами и форматами документов, включая цифровые и отсканированные файлы.

Изображение и его предварительная обработка
Начальным этапом в системе является извлечение изображения с текстовой информацией. Это может быть сканированный документ, снимок или видеозапись. Прежде чем приступить к работе, требуется провести предварительную обработку изображения для его улучшения. В данном процессе используются методы, такие как удаление шумов, увеличение контрастности, корректировка выравнивания и поворот изображения. Предварительная обработка способствует улучшению разборчивости текста и повышению точности его распознавания.
Разделение изображения на сегменты
После предварительной обработки изображения происходит его сегментация на отдельные элементы, такие как символы, слова или абзацы. Сегментация позволяет выделить каждый элемент для последующего анализа. Существуют различные методы сегментации, включая использование пороговых значений, контуров и нейронных сетей. Каждый метод имеет свои преимущества и подходит для определенных типов изображений.
Выделение признаков из сегментированного изображения
После того как изображение было сегментировано, осуществляют процесс выделения признаков для каждого компонента. Это включает в себя изучение формы символов, текстурных деталей и различных других свойств. Выделение признаков дает возможность преобразовать каждый текстовый элемент в числовой вектор, который впоследствии будет применяться.
Определение и идентификация объектов
На основе извлеченных признаков система применяет методы машинного обучения, такие как нейронные сети или статистические модели, для определения содержимого каждого элемента. Классификация может быть двухуровневой, где система сначала определяет, является ли объект символом или не символом, а затем распознает конкретный символ или текст. Современные системы OCR достигают высокой точности и способны работать с различными языками, шрифтами и стилями письма.
В результате системы OCR становятся надежным и эффективным инструментом для автоматизации обработки текстовой информации в различных областях.
Техники
- Изображения Распознавание текста на изображениях является одной из основных техник. Оно позволяет извлекать текстовую информацию с различных типов изображений, включая фотографии, сканы документов и кадры с видео. Вот некоторые методы и техники, применяемые в распознавании текста на изображениях:
— Сегментация изображения на текстовые регионы. Для этого применяются алгоритмы, основанные на цветовых свойствах, текстуре или контексту окружающих объектов. — Преобразование текстовых регионов в машинно-читаемый текст. Это может быть достигнуто с использованием методов машинного обучения, таких как рекуррентные нейронные сети или скрытые марковские модели. — Постобработка и исправление ошибок. Используются алгоритмы коррекции опечаток, проверки синтаксиса и контекстуального анализа для улучшения качества.
- Лица Это еще одна важная техника. Она позволяет идентифицировать лица людей на изображениях или в видеопотоке. Вот некоторые методы:
— Определение лиц на фото с применением методов, основанных на признаках, таких как глаза, нос, рот и контуры лица. — Выделение характеристик лица, включая геометрические параметры и текстурные узоры. — Сопоставление полученных характеристик с информацией из базы данных известных личностей для идентификации или подтверждения личности.
- Штрихкоды и QR-коды Важная техника оптического распознавания, широко применяемая в розничной торговле, логистике и управлении запасами. Вот некоторые методы, которые она использует:
— Обнаружение и выделение кода на изображении с помощью алгоритмов обработки изображений и компьютерного зрения.
— Декодирование информации, закодированной в штрихкоде или QR-коде, с использованием специальных алгоритмов декодирования. — Интерпретация распознанной информации и ее использование для трекинга товаров, идентификации продуктов или передачи данных.
- Рукописный текст Распознавание рукописного текста — это сложная задача, которая требует учета естественной вариативности почерка. Для этого используются следующие методы:
— Обнаружение и сегментация рукописного текста на изображении. — Извлечение признаков из сегментированного текста, таких как форма букв, линии и углы. — Применение методов машинного обучения, таких как рекуррентные нейронные сети или скрытые марковские модели, для классификации и распознавания рукописных символов и слов.
Применение
Бизнес-сфера
Технология охватывает множество аспектов в сфере бизнеса. Рассмотрим несколько направлений, где она используется:
Автоматизация обработки документов и управление документооборотом. Распознавание: — печатной и рукописной информации для анализа и извлечения данных; — товаров на основе штрихкодов и QR-кодов, а также их классификация; — лиц для систем аутентификации и безопасности.
Медицина и фармацевтика
В медицине и фармацевтике системы имеют множество применений:
— Распознавание и классификация медицинских изображений, таких как рентгеновские снимки и снимки МРТ, а также символов на медицинской упаковке и этикетках для идентификации препаратов.. — Извлечение и анализ данных из медицинских отчетов и историй болезни.
Защита и мониторинг видео
OCR распознавания играют важную роль в обеспечении безопасности и видеонаблюдении:
— Распознавание лиц для идентификации и аутентификации персонала или подозрительных личностей, автомобильных номерных знаков для контроля доступа и слежения за транспортными средствами. — Анализ видеопотока для обнаружения нежелательных событий и поведения.
Транспорт и логистика
В транспортной и логистической сфере оно тоже играет важную роль:
— Идентификация штрих-кодов и QR-кодов для мониторинга грузов и управления запасами, а также для автоматического контроля доступа и повышения безопасности пассажиров. — Изучение транспортных потоков и регулирование дорожного движения с использованием распознавания автомобильных номеров.



Вызовы и будущие направления развития- Проблемы и ограничения текущих системСуществуют некоторые проблемы и ограничения, с которыми сталкиваются текущие системы: — Сложности в распознавании текста с плохим качеством изображения или в условиях низкой освещенности, а также рукописного текста из-за его вариативности и субъективности. — Возможность ложных срабатываний или неверной классификации из-за изменения внешнего вида лиц или особенностей окружающей среды.
- Искусственный интеллект и машинное обучениеЕго будущее связано с развитием и применением искусственного интеллекта и методов машинного обучения: — Использование глубокого обучения и нейронных сетей для повышения точности и обработки сложных входных данных. — Интеграция контекстуального анализа и семантического понимания для более высокоуровневого анализа и интерпретации распознанной информации. — Развитие методов самообучения и адаптивности для улучшения производительности и адаптации к различным сценариям.
OCR является мощным инструментом для извлечения информации из изображений. Техники распознавания текста, лиц, штрихкодов и рукописного текста находят широкое применение в различных областях, включая бизнес, медицину, безопасность и транспорт. Однако существуют вызовы и ограничения, которые можно преодолеть с помощью развития искусственного интеллекта и методов машинного обучения. Оно будет продолжать развиваться и играть все более важную роль в обработке и анализе визуальных данных.
Большие данные — Big Data в.
В мире банковской деятельности информация является ключевым ресурсом. Она позволяет принимать более обоснованные решения, предоставлять качественные услуги.
Big data — большие данные в.
Большие данные – это понятие, которое охватывает обширные, сложные и разнородные массивы информации, которые не поддаются эффективной обработке.

Нормализация базы данных SQL
Каждый профессионал, работающий в области информационных технологий, сталкивается с необходимостью проектирования структуры данных. База данных — это.
Остались вопросы?
Оставьте контактные данные и мы свяжемся с вами в ближайшее время
OCR (Optical Character Recognition)

Деятельность любой компаний связана с документированием, и в частности, с использованием в работе таких информационных носителей, как квитанции, бланки, контракты, выдержки из печатных изданий, распечатки. Однако все эти форматы неудобно редактировать и дополнять на компьютере, поскольку они представляют собой графические объекты и, чтобы изменить текст, приходится дописывать/переписывать его вручную. В этой ситуации на помощь сотрудникам придет технология Optical Character Recognition, которая позволяет преобразовывать изображения в текстовый формат. Она используется не только для удобства работы, но и для обеспечения сохранности конфиденциальных данных, которые могут пересылаться в виде изображений. Разберемся, как функционирует уникальная технология, в каких сферах будет полезна, каким образом внедряется и эксплуатируется.
Что такое OCR и какие задачи он решает
Это технология оптического чтения символов, позволяющая автоматически анализировать текст с изображений и переводить его в формат, с которым может работать компьютер. Как происходит этот процесс?
Процесс работы OCR обычно протекает в несколько этапов:
- Предобработка изображений. Это первый этап процесса OCR, во время которого система «улучшает» качество изображения, оптимизируя его для дальнейшего распознавания текста. Обычно предобработка предполагает такие действия, как коррекция геометрии, удаление шума, бинаризация, сегментация и выделение текста.
- Распознавание текста. После первичной обработки изображения OCR-система приступает к собственно распознаванию текста – идентификации символов на основе их анализа. Используя алгоритмы машинного обучения, OCR-система сравнивает символы на изображении с заранее обученными шаблонами, находит точные совпадения и, таким образом, определяет исходный текст.
- Постобработка текста. После распознавания текста OCR-система может «улучшить» его, т. е. провести проверку орфографии, грамматики и пунктуации с использованием имеющихся в ее арсенале словарей, что позволит более точно воспроизвести текст.
- Экспорт текста. После того как текст был распознан и отредактирован, OCR-система может экспортировать его в различные редактируемые форматы, такие как TXT, PDF, Word и другие. Экспортированный текст может быть использован для дальнейшей работы с ним, внесения правок или индексирования.
Для улучшения точности распознавания текста и обработки более сложных документов OCR-системы могут использовать дополнительные технологии, такие как искусственный интеллект и глубокое обучение.

Сферы применения OCR
Технология оптического распознавания символов (OCR) находит активное применение в множестве отраслей и сфер. Рассмотрим некоторые из них:
- Финансы и банковское дело: OCR используется для распознавания рукописных или напечатанных данных на чеках, счетах, бланках и документах, что помогает в автоматизации процессов бухучета и банковского дела.
- Здравоохранение: OCR используется для распознавания текста в формах заключений медицинских обследований, рецептах, персональных картах пациентов, что позволяет снизить риски ошибок и повысить эффективность обработки информации.
- Образование: в образовательных учреждениях OCR используется для сканирования и распознавания текста из учебников, авторских статей, документов, что упрощает процесс создания электронных ресурсов и учебных материалов.
- Транспорт: OCR используется для распознавания номеров автомобилей на дорожных камерах, идентификации документов при автоматической оплате проезда и в системах безопасности.
- Информационная безопасность: технология помогает предотвращать утечки конфиденциальных данных, представленных в формате изображений.
Это лишь несколько примеров применения OCR. Технология OCR продолжает развиваться и проникать в новые области, улучшая процессы работы и повышая производительность.
Эксперты по анализу данных подразделяют технологии OCR на типы на основе практики их применения. К примеру:
- Программы простого оптического распознавания символов – один из базовых видов OCR-технологий. Они основаны на механизме применения множества созданных и сохраненных шаблонов шрифтов и изображений текста в качестве эталонов. Программное обеспечение OCR использует алгоритмы сравнения эталонов с внутренней базой данных для посимвольного анализа текста на графических объектах.
- Программы интеллектуального распознавания символов (Intelligent Character Recognition, ICR) представляют собой более продвинутый вид технологий OCR, в отличие от программ простого оптического распознавания символов. ICR-технологии используют алгоритмы искусственного интеллекта и машинного обучения для распознавания рукописного текста и других сложных форм текста, которые не могут быть распознаны простыми OCR-системами. ICR-технологии способны распознавать различные стили почерка и шрифты, а также анализировать контекст, чтобы повысить точность распознавания. Это делает их особенно полезными для обработки больших объемов документов, содержащих рукописный текст, таких как анкеты, печатные формы, бланки и прочие деловые «бумаги».

Какие нарушения безопасности можно предотвратить с помощью Optical Character Recognition
Технологии распознавания изображений помогают обнаруживать и предотвращать утечки или намеренные сливы конфиденциальных данных. Благодаря им можно «прочитать» в переписках фото корпоративных документов, паспортов сотрудников, печатей организации, финансовых отчетов и т. д. Алгоритмы сработают, даже если графические объекты будут намеренно деформированы (растянуты, наложены друг на друга, перевернуты).
Обеспечение безопасности корпоративной информации с использованием Solar Dozor
OCR-технологии часто реализуются в таких важных системах защиты, как (Data Loss Prevention), которые используются для предотвращения утечек конфиденциальных данных. Алгоритмы оптического распознавания присутствуют и в составе решения Solar Dozor. Технология работает следующим образом:
- Dozor Core выявляет данные в формате изображений (сканы документов или фотографии).
- Изображения отправляются в Dozor OCR.
- После обработки Dozor OCR преобразует изображения в текстовую информацию (TEXT/PLAIN) и передает ее обратно в Dozor Core.
- Dozor Core анализирует эту текстовую информацию на предмет соблюдения политики безопасности организации.
Алгоритмы OCR помогают упростить работу с печатными документами и различными графическими форматами файлов, защититься от утечки конфиденциальных данных. Эта технология присутствует в функционале зрелых DLP-решений, в том числе Solar Dozor.
ДРУГИЕ СТАТЬИ ПРОДУКТА
Еще больше о наших возможностях
Сложности применения технологий OCR в DLP-системах, или Как мы OCR готовим

Задача по распознаванию изображений (OCR) сталкивается с множеством трудностей. Иногда изображение невозможно распознать из-за необычной цветовой палитры или различных искажений. В других случаях заказчик требует распознавать все изображения без каких-либо исключений, что далеко не всегда реально. Проблемы различны, и их решение не всегда можно найти мгновенно. В этой статье мы поделимся несколькими практическими рекомендациями, основанными на нашем опыте разрешения настоящих ситуаций с заказчиками.
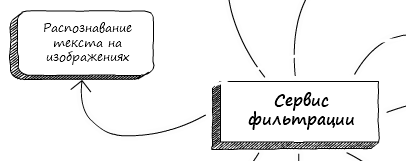
Но сначала немного истории. Прошло немало времени с момента выхода статьи о том, как мы переписывали сервис фильтрации. В ней мы немного рассказали о фильтрации и обработке сообщений, о том, как устроен наш сервис фильтрации в целом. В этот раз мы постараемся ответить на вопрос «А как же мы обрабатываем изображения, как взаимодействуют сервисы, и что происходит с системой под нагрузкой?» Если оперировать статьей про сервис фильтрации, то сейчас мы будем рассматривать только одну ветку взаимодействия сервисов – это взаимодействие сервиса фильтрации и OCR.
Что такое OCR?
Прежде чем говорить о взаимодействии сервисов и проблемах применения OCR попробуем понять, что такое OCR. Возьмем сложное определение из Википедии.
Оптическое распознавание символов (англ. optical character recognition, OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные, использующиеся для представления символов в компьютере (например, в текстовом редакторе).
Если говорить просто, то взяли картинку, отправили на распознавание, дальше магия вне Хогвартса и получили текст.

Также можно использовать определение OCR с ресурса ABBYY, которое выглядит более лаконичным.
Оптическое распознавание символов (англ. Optical Character Recognition – OCR) – это технология, которая позволяет преобразовывать различные типы документов, такие как отсканированные документы, PDF-файлы или фото с цифровой камеры, в редактируемые форматы с возможностью поиска.
А зачем оно (распознавание изображений) нам нужно?
Распознавание изображений мы можем использовать хоть на домашнем ПК для преобразования цифровых изображений в редактируемые текстовые данные.Но стоящая перед нами задача гораздо шире (DLP-система все-таки): нам нужно контролировать поток информации в организации.
DLP-системы давно появились на рынке и сейчас входят в привычный арсенал корпоративных СЗИ (средств защиты информации). Перед DLP стоит задача контроля движения графической информации (отсканированных документов, скриншотов, фотографий). Причем не просто контроля движения графических файлов, а в первую очередь, анализа их содержимого. Система должна уметь понимать, с какой именно информацией она столкнулась, сравнить с образцами защищаемой информации и обеспечить возможности для дальнейшего поиска этой информации пользователем. Применение других средств анализа, таких, как сравнение с цифровыми отпечатками, вычисление хэша, анализ по формату, размеру и структуре файла, также являются ценными источниками информации, но не позволяют ответить на вопрос: «а какой текст передается в данной картинке?» А между тем текст все еще является самым распространённым носителем структурированной информации, в том числе в графических файлах.
Традиционно для распознавания графической информации используют технологию OCR (что это такое мы уже определили). На самом деле OCR – это вообще единственный класс технологий, которые предоставляют возможности извлечения текстовой информации из изображений. Поэтому тут речь не то чтобы о традиционном подходе, а скорее об отсутствии выбора.
Сколько изображений приходит на обработку в DLP-систему?
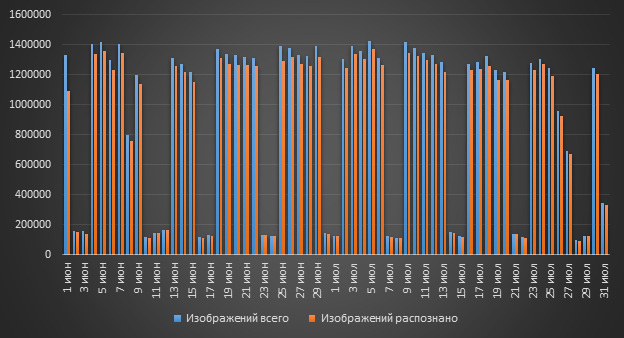
Разве можно обойтись без OCR? Действительно ли поступает так много изображений в DLP, что использование OCR становится необходимым? Ответ на данный вопрос – «Да!». В течение суток в систему может загружаться свыше миллиона изображений, и каждый из них может содержать текст.
OCR в составе DLP-системы «Ростелеком–Солар» используются в компаниях нефтегазовой отрасли и госструктурах. Все заказчики используют возможности OCR для детектирования конфиденциальных данных в отсканированных документах. Что может содержаться в такой «графике»? Да все, что угодно. Это могут быть сканы различных внутренних документов, например, содержащие ПДн.
Или информация из категории коммерческой тайны, ДСП (для служебного пользования), финансовая отчетность и т.п.
Как OCR распознает изображения?
Процесс выглядит следующим образом: DLP перехватывает сообщение, содержащее изображение (скан документа, фотографию и т.п.), определяет, что изображение действительно есть в сообщении, извлекает его и отправляет на распознавание в модуль OCR. На выходе DLP получает информацию о содержимом изображения (да и сообщения в целом) в виде извлеченного TEXT/PLAIN.
Если говорить о взаимодействии сервисов непосредственно в нашей системе Solar Dozor, то сервис фильтрации отправляет изображения (если они есть) из сообщения в сервис извлечения текста изображений (OCR). Последний, после завершения распознавания, отдаёт полученный текст в mailfilter. Получается что-то вроде жонглирования изображениями и текстом.

Изучим механизм распознавания более детально, опираясь на функционал OCR-технологий ABBYY, которые применяются в нашей системе DLP.
Пожалуй, главной проблемой для OCR при распознавании текста является написание того или иного символа. Если взять любую букву алфавита (например, русского или английского), то для каждой мы найдем несколько вариантов написания. OCR-движки решают эту задачу несколькими способами:
- Нахождение символа по паттерну. Например, с использованием различных шрифтов написания.
- Выявление признаков написания символа.
Про работу OCR достаточно много различных статей. Подробно о работе OCR можно почитать, например, здесь https://sysblok.ru/knowhow/iz-pikselej-v-bukvy-kak-rabotaet-raspoznavanie-teksta/
Как готовить OCR в целом для распознавания?
Мы уже выяснили, что в DLP может попадать более миллиона изображений. Но все ли изображения из этого миллиона нам полезны?
Ответ на вопрос более чем очевиден – конечно, нет. Но почему нам будут полезны не все изображения? Ответ на этот вопрос тоже достаточно прозрачен: в почте «гуляет» очень много картинок из подписей в сообщениях. Наверное, 90% сообщений (если не больше) будут содержать логотип компании.
Картинки такого рода имеют слишком маленький размер для распознавания, и текст в них может отсутствовать полностью. В связи с этим, мы настоятельно рекомендуем устанавливать ограничения на размеры изображений, подлежащих распознаванию. При этом такие ограничения следует определять как по минимальному, так и по максимальному размеру. Вероятность отправки на обработку громоздких файлов ниже, чем у изображений из подписи, но все же остается достаточно высокой.
Стоит отметить, что цифровые изображения часто имеют разные дефекты. Маловероятно, что в DLP всегда будут попадать сканы документов в хорошем разрешении. Скорее наоборот, сканы всегда будут не в лучшем качестве и с большим количеством дефектов.
Например, в цифровом фото может быть искажена перспектива, оно может оказаться засвеченным или перевернутым, строки скана – изогнутыми. Такие искажения могут усложнять распознавание. Поэтому OCR-движки могут предварительно обрабатывать изображения, чтобы подготовить их к распознаванию. Например, изображение можно покрутить, преобразовать в ч/б, инвертировать цвета, скорректировать перекосы строк. Все это можно задать в настройках OCR и, как следствие, эти инструменты могут помочь улучшить распознавание текста в изображениях.
В итоге мы пришли к базовым принципам подготовки OCR к распознаванию:
- Определить размеры изображений, которые мы будем распознавать, как в pixels, так и в Мб.
- Включить препроцессинг изображений.
На что еще следует обращать внимание при подготовке OCR, мы ниже расскажем на примерах использования этой технологии в боевой практике.
Какие челленджи возможны при эксплуатации OCR в DLP под большой нагрузкой?
1. Чрезмерно большие ограничения на габариты идентифицируемых изображений
Начнем с того, о чем мы уже упомянули, – с лимитов.
Исходя из нашей практики, заказчики часто устанавливают слишком широкие лимиты на размеры распознаваемых графических файлов. Да, чтобы OCR работал хорошо, нужно ограничивать размеры изображений. Но заказчики стремятся контролировать все подряд, полагая, что даже в картинке размером 100×100 pixels и 5 Кб могут утечь ценные данные. В целом, конечно, 100х100 pixels и 5 Кб тоже ограничения, но слишком уж низки эти пороги.
Другая крайность – стремление распознать тяжелые файлы по несколько сотен Мб. Понятно, что через корпоративную почту такие изображения не пролезут из-за ограничений на размер пересылаемых сообщений. Но вот по другим каналам перехвата (например, с корпоративных сетевых шар) увесистые файлы настойчиво стремятся распознавать. Если же заказчик хочет добавить к этому еще и большой объем high-res изображений, то для этого нужно иметь соответствующие серверные мощности. В итоге, при столь широких минимальных и максимальных порогах на размер распознаваемых файлов создается высокая нагрузка на процессор на серверах, что замедляет работу всех подсистем.
Что здесь можно порекомендовать? Прежде всего проанализировать, в какой используемой в компании «графике» содержатся конфиденциальные данные, после чего прикинуть разумные минимальные и максимальные ограничения на размеры контролируемых изображений. Обычно мы рекомендуем заказчикам зафиксировать нижнюю границу разрешения изображения от 200 pixels, в идеале от 400 pixels (по осям X и Y), и размера файлов не меньше 20 Кб, лучше больше. Также не имеет смысла отправлять в OCR тяжеловесные изображения – они элементарно перегрузят ваши сервера и не факт, что будут распознаны.
2. Очереди для фильтрации и время ожидания обработки запросов
Чрезмерная нагрузка на серверы, возникающая по вышеописанным причинам, ведет по цепочке к увеличению времени распознавания изображений и обработки запросов в целом. В результате в DLP-системе начинает увеличиваться очередь сообщений на фильтрацию. Кроме того, в OCR-модуль могут приходить графические файлы, которые в принципе невозможно распознать (тяжелые файлы, низкое качество и т.п.), в результате чего возникают таймауты обработки изображений. Если нераспознаваемых файлов поступает много, а в системе установлены высокие таймауты на распознавание, сервис фильтрации ждёт, пока этот таймаут наступит, и только потом приступает к обработке следующего запроса. Весь процесс обработки может серьезно тормозиться.
Что можем посоветовать? При возникновении очереди на обработку графических изображений нужно посмотреть настройки OCR в DLP-системе и попробовать найти причину торможения. Это может происходить, например, из-за проблем межпроцессного взаимодействия на самом сервере. Вообще, эти проблемы заслуживают отдельного разговора. Некоторые подробности по общим вопросам можно узнать из статьи «Знакомство с межпроцессным взаимодействием на Linux».
Кроме этого важным моментом при настройке OCR является выставление адекватных таймаутов на распознавание изображений. В общем случае достаточно 90 секунд, чтобы изображение точно распозналось. Если из изображения не извлекся текст за 90 секунд, то можно предположить, что OCR не распознает изображение в принципе. В этом месте также могут возникать проблемы конфигурирования OCR, когда выставляют высокие таймауты на распознавание и тем самым делаются попытки распознать нераспознаваемое.
Что еще может стать причиной таймаута? Здесь мы снова вернемся к вопросу конфигурирования системы. Сервис фильтрации, как и сервис OCR, оперирует тредами, которые обрабатывают сообщения и изображения. Система может быть некорректно сконфигурирована в части количества обработчиков сервиса фильтрации и количества обработчиков OCR.
К примеру, в системе фильтрации будет множество потоков для обработки, тогда как у OCR будет всего один. В результате в определенные моменты OCR может не справляться с обработкой всех запросов на распознавание, что приведет к возникновению таймаутов при анализе изображений.
Подобное поведение системы наводит на мысли о проблемах проектирования и багах в архитектуре, но на самом деле это не так. Архитектура нашей DLP предоставляет возможности гибкой конфигурации системы и настройки её под нужды заказчиков. Например, мы можем достаточно просто настроить один OCR на работу с двумя сервисами фильтрации без ущерба производительности.
3. Нераспознаваемые изображения
Если в DLP-систему попадает на анализ изображение, которое OCR не может распознать, существует несколько вариантов решения проблемы.
По каким причинам изображения могут не распознаваться? Например, по следующим:
1. Необычная палитра цветов на картине.
2. Низкое разрешение изображения.
3. Неправильная ориентация изображения и содержащегося в нем текста в пространстве.
4. Перекосы строк и искажения пропорций текста в изображении и др. Приведем пример: у одного из заказчиков в процессе мониторинга выяснилось, что OCR не распознает pdf-документы, выполненные в нестандартной цветовой схеме. То есть изображение извлекалось из PDF-документа в штатном режиме, но когда дело доходило до обработки OCR-модулем, тот не понимал цветовую схему картинки и выдавал на выходе «квадрат Малевича». В нашем интерфейсе картинка выглядела примерно так:

В OCR-движках заложены различные функции автоматической коррекции изображения, которые сильно повышают шансы на успешное распознавание содержащегося в нем текста. Однако, на практике эти волшебные инструменты не всегда срабатывают. В данном конкретном случае мы донастроили для заказчика OCR-модуль таким образом, чтобы он распознавал эту нестандартную цветовую схему.
5. Непараметричность одного из аспектов документа относительно установленных размеров распознаваемых изображений.
Например, в конфигурации системы заданы границы размеров распознаваемых изображений 200х1000 pixels, а в OCR поступил файл размером 500х1500 pixels (верхний лимит превышен). В этом случае необходимо исправить настройки OCR для распознавания таких изображений. Это, пожалуй, один из самых популярных сценариев донастройки системы после того, как нам говорят, что OCR не работает.
Почему OCR не на агентах?
OCR в DLP-системах реализуется в двух вариантах – на агентах и на серверах. Мы являемся сторонниками второго подхода, поскольку распознавание изображений прямо на рабочей станции создает высокую нагрузку на ее процессор и, соответственно, тормозит работу других приложений. OCR сама по себе весьма прожорливая технология даже для серверов, и её применение требует правильного планирования процессорных мощностей и контроля эффективности.
При этом многие отечественные компании, в особенности в госсекторе, до сих пор владеют достаточно старым парком ПК. Что происходит в этом случае? Пользователи начинают жаловаться ИТ-подразделению на «торможение» ПК, а айтишники в конце концов выясняют, что причиной торможения является OCR-модуль DLP-системы. Это раздражает и их, и пользователей, которые не могут оперативно решать рабочие задачи. В конечном итоге все это складывается в головную боль для безопасника, у которого и других задач полно.
Использование OCR на агентах оправдано лишь тогда, когда DLP-система работает «в разрыв». В этом случае распознавание изображения должно происходить ровно в тот момент, когда пользователь совершает действия с этим графическим файлом на своей рабочей станции. То есть DLP-система должна мгновенно решить судьбу документа, содержащего это изображение – разрешить его к отправке/копированию или запретить. Но на практике только единицы заказчиков используют DLP-систему в режиме активной блокировки, и это касается не только нашей собственной DLP. Здесь работает принцип «все, что можно вынести для проверок на сервер, должно выполняться на сервере».
Итого
Технологии оптического распознавания символов (OCR) открывают новые горизонты для анализа графических изображений, и мы дополнительно предоставляем общие советы по настройке системы. Однако в рамках конкретных проектов может возникнуть необходимость в донастройке работы модуля OCR в соответствии с уникальными требованиями заказчика как на стадии тестирования и внедрения, так и в процессе его полноценной эксплуатации. Это не просто приемлемо – это единственно правильный подход, который обеспечит значительный эффект и повысит эффективность работы OCR в компании, минимизируя риски утечки конфиденциальных данных через графические материалы.
Никита Игонькин, ведущий инженер сервиса компании «Ростелеком-Солар»
- ocr-технологии
- dlp-системы
- распознавание изображений
- Блог компании Солар
- Информационная безопасность
- Обработка изображений
- Софт



